

Blog
Blog
What is OpenAI's CLIP and how to use it?
CLIP is a multimodal model that combines knowledge of English-language concepts with semantic knowledge of images
In January 2021 OpenAI released CLIP (Contrastive Language-Image Pre-Training), a zero-shot classifier that leverages knowledge of the English language to classify images without having to be trained on any specific dataset. It applies the recent advancements in large-scale transformers like GPT-3 to the vision arena.
The results are extremely impressive; we have put together a CLIP tutorial and a CLIP Colab notebook for you to experiment with the model on your own images.
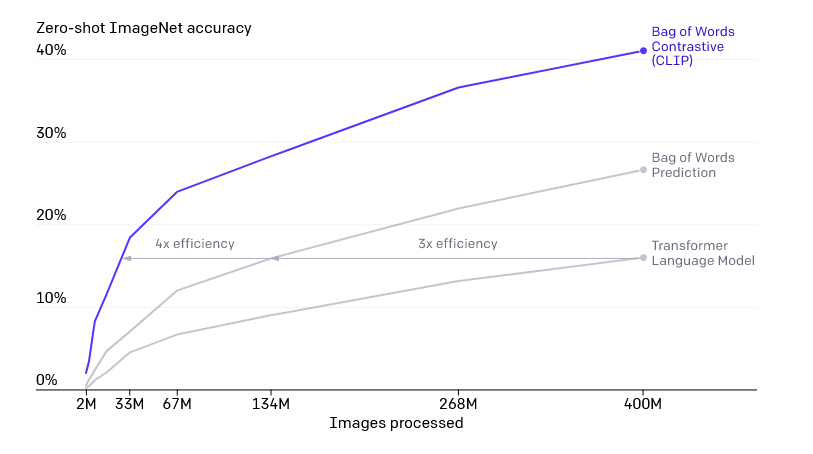
Training Efficiency: CLIP is among one of the most efficient models with an accuracy of 41% at 400 million images, outperforming other models such as the Bag of Words Prediction (27%) and the Transformer Language Model (16%) at the same number of images. This means that CLIP trains much faster than other models within the same domain.
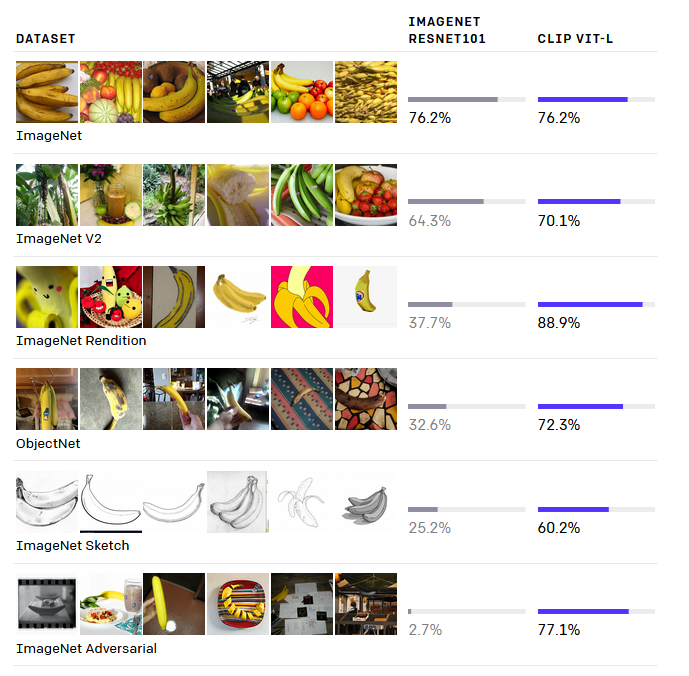
Generalization: CLIP has been trained with such a wide array of image styles that it is far more flexible and than other models like ImageNet. It is important to note that CLIP generalizes well with images that it was trained on, not images outside of its training domain. Pictured below are some of the different image styles:
Using OpenAI CLIP: https://blog.roboflow.com/how-to-use-openai-clip/
First, install Inference:
To classify images with CLIP, use the following code:




